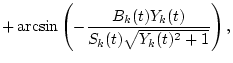In this paper, it is assumed that the desired signal f1(t) is a harmonic complex tone, where F0(t) is the fundamental frequency.
The proposed model segregates the desired signal from the mixed signal by constraining the temporal differentiation of Ak(t),
![]() , and F0(t).
, and F0(t).
The proposed model is composed of four blocks: an auditory-motivated filterbank, an F0 estimation block, a separation block, and a grouping block, as shown in Fig. ![]() .
Constraints used in this model are shown in Table 1.
.
Constraints used in this model are shown in Table 1.
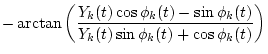
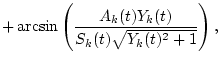
![$\sigma_\theta=\int_{t_a}^{t_b} [\theta_{1k}^{(R+1)}(t)]^2dt \Rightarrow \min$](img25.gif)