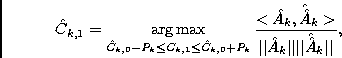An overview of signal processing of the proposed model is shown in Fig. ![]() .
First, noisy vowel /a/ f(t) shown in Fig.
.
First, noisy vowel /a/ f(t) shown in Fig. ![]() A (the SNR of f(t)is 10 dB) is decomposed into Sk(t) and
A (the SNR of f(t)is 10 dB) is decomposed into Sk(t) and ![]() as shown in Figs.
as shown in Figs. ![]() B and C, respectively.
Next, F0(t) is estimated as shown in Fig.
B and C, respectively.
Next, F0(t) is estimated as shown in Fig. ![]() D.
The concurrent time-frequency region of the desired signal f1(t) is determined using constraints (i) and (iii) as shown in Figs.
D.
The concurrent time-frequency region of the desired signal f1(t) is determined using constraints (i) and (iii) as shown in Figs. ![]() E and F.
Finally, the instantaneous amplitudes and the instantaneous phases of the two signals are determined from Sk(t) and
E and F.
Finally, the instantaneous amplitudes and the instantaneous phases of the two signals are determined from Sk(t) and ![]() using constraints (ii) and (iv).
The determined Ak(t) and
using constraints (ii) and (iv).
The determined Ak(t) and
![]() are shown in Figs.
are shown in Figs. ![]() H
and I, respectively.
The segregated signal
H
and I, respectively.
The segregated signal
 is shown in Fig.
is shown in Fig. ![]() J.
In this figure, note that the segregated Bk(t),
J.
In this figure, note that the segregated Bk(t),
![]() , and
, and
![]() are omitted.
are omitted.