

次に7表情の内,6表情をtraining data,残り1表情をtest data
として複数の固有ベクトルを用いて個人識別を行った.
個人識別には入力ベクトル ![]() (test data)との距離が最短となる辞書ベ
クトル
(test data)との距離が最短となる辞書ベ
クトル ![]() (training dataのmについての
(training dataのmについての ![]() の平均;
の平均; ![]() )に対応するfを入力顔画像の識別結果とした.
距離は次式によって与えられるEuclid距離Dを使用した.
)に対応するfを入力顔画像の識別結果とした.
距離は次式によって与えられるEuclid距離Dを使用した.
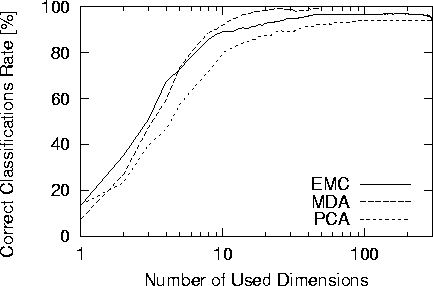
識別に用いた特徴ベクトルの次元数と識別率との関係を図 に示す.
尚,識別率は,training dataとtest dataの全組合わせ(7通り)について,
test dataのみから計算されたものである.
また,使用次元数49の識別率を表にまとめる.
PCAに比べ,EMC,MDA共に少ない使用次元数で高い識別率を得た.
特にMDAは少ない使用次元数で識別率が向上している.
EMCよりもMDAの方が識別率が良い理由として,
MDAの軸が斜交であることより級間分散を大きくするような強調効果が起こる
ことが考えられる.
に示す.
尚,識別率は,training dataとtest dataの全組合わせ(7通り)について,
test dataのみから計算されたものである.
また,使用次元数49の識別率を表にまとめる.
PCAに比べ,EMC,MDA共に少ない使用次元数で高い識別率を得た.
特にMDAは少ない使用次元数で識別率が向上している.
EMCよりもMDAの方が識別率が良い理由として,
MDAの軸が斜交であることより級間分散を大きくするような強調効果が起こる
ことが考えられる.