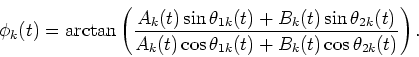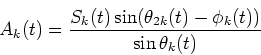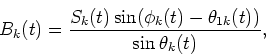First, only the mixed signal f(t), where
f(t)=f1(t)+f2(t), can be observed in the proposed model.
Here, f1(t) is the desired signal and f2(t) is a noise or the other signal.
The observed signal f(t) is decomposed into its frequency components by an auditory-motivated filterbank (the number of channels is K).
The output of the k-th channel Xk(t) is represented by
Second, the outputs of the k-th channel, which correspond to f1(t) and f2(t), are assumed to be
Hence, since the instantaneous amplitude Sk(t) and the instantaneous output phase ![]() are observable (see Sec. 3.1.1), and if the instantaneous input phases
are observable (see Sec. 3.1.1), and if the instantaneous input phases
![]() and
and
![]() are determined, then Ak(t) and Bk(t) can be determined by the above equations.
are determined, then Ak(t) and Bk(t) can be determined by the above equations.
Finally, f1(t) and f2(t) can be reconstructed by using the grouping of the instantaneous amplitude and the instantaneous phase for all channels.
Thus,
![]() and
and
![]() are the reconstructed f1(t) and f2(t), respectively.
are the reconstructed f1(t) and f2(t), respectively.
However, in the above formulation, it is difficult to uniquely and simultaneously determine the instantaneous amplitudes (Ak(t) and Bk(t)) and the instantaneous phases (
![]() and
and
![]() )
using Sk(t) and
)
using Sk(t) and ![]() ,
because there are currently no equations for determining two such instantaneous phases and the segregation of two acoustic sources is an ill-inverse problem.
Therefore, in this paper, we try solving the problem of segregating two acoustic sources by constraining the desired signal using the four regularities.
,
because there are currently no equations for determining two such instantaneous phases and the segregation of two acoustic sources is an ill-inverse problem.
Therefore, in this paper, we try solving the problem of segregating two acoustic sources by constraining the desired signal using the four regularities.