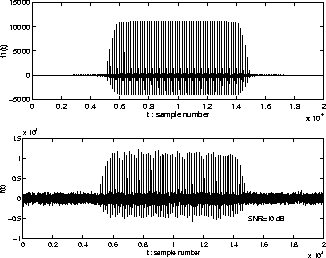
This simulation assumes that f1(t) is a synthetic vowel, as shown in Fig. 5, where F0=125 Hz, NF0=40, and it is the vowel /a/ synthesized by LMA, and that f2(t) is a bandpassed random noise with a bandwidth of about 6 kHz. Three types of f(t) are used as simulation stimuli, where the SNRs of f(t) are from 0 to 20 dB in 10-dB steps. The mixed signal for SNR=10 dB is plotted in Fig. 5.
The simulations were carried out using the three mixed signals.
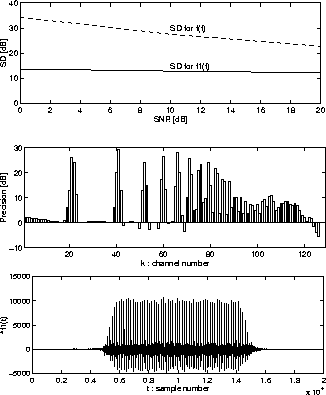
The average SDs of f1(t) and f(t) are shown in Fig. 6.
Hence, it is possible to reduce the SD by about 15 dB as noise reduction by using the proposed method.
For example, when the SNR of f(t) is 10 dB, the proposed method can segregate Ak(t) with high precision, as shown in Fig. 7, and it can extract the
![]() shown in Fig. 7 from the f(t) shown in Fig. 5.
Therefore, the proposed model can also extract the amplitude information of speech f1(t) from a noisy speech f(t) with high precision when speech and noise exist in the same frequency region.
Hence, this method can be used to extract a speech signal from noisy speech.
shown in Fig. 7 from the f(t) shown in Fig. 5.
Therefore, the proposed model can also extract the amplitude information of speech f1(t) from a noisy speech f(t) with high precision when speech and noise exist in the same frequency region.
Hence, this method can be used to extract a speech signal from noisy speech.