


Next: Evaluation of the constrains
Up: Segregation of vowel in
Previous: Overview of the proposed
To show that the proposed model can segregate the desired signal f1(t) from a noisy signal f(t) precisely even in waveforms, we evaluated the following two issues by using four simulations.
One is to evaluate the advantage of constraints, and the other one is to evaluate whether or not the proposed model can precisely segregate the desired vowel from noisy vowel.
In these simulations, we used the following signals:
- (a)
- noisy synthesized AM-FM harmonic complex tone (LMA-synthesis vowel /a/) [Unoki and Akagi1998];
- (b)
- noisy real vowel (/a/, /i/, /u/, /e/, /o/);
- (c)
- noisy real continuous vowel (/aoi/); and
- (d)
- concurrent double vowel (signal (b) + signal (c)),
where the noise was pink or white noise and the SNRs of noisy signals ranged from 5 to 20 dB in 5-dB steps.
The speech signals were the Japanese vowels of four speakers (two males and two
females) in the ATR-database [ATR Tech. Rep.1988].
We used an evaluation measure such as SNR to evaluate the segregation performance of the proposed method, as defined by
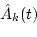 |
(18) |
where f1(t) is the original signal and
 is the segregated signal.
This measure is called ``segregation accuracy.''
is the segregated signal.
This measure is called ``segregation accuracy.''
Next: Evaluation of the constrains
Up: Segregation of vowel in
Previous: Overview of the proposed
Masashi Unoki
2000-10-26