


Next: Considerations
Up: Simulations
Previous: Evaluation of the constrains
Figure:
Segregation accuracy for simulation 1: (a) bandpassed pink noise, (b) bandpassed white noise.
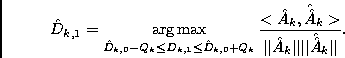 |
Figure:
Segregation accuracy for simulation 2: (a) bandpassed pink noise, (b) bandpassed white noise.
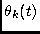 |
Figure:
Example of simulation 2: (a) original /a/ f1(t), (b) mixed signal f(t), (c) fundamental frequency F0(t), (d) segregated signal
 .
.
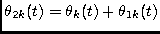 |
Figure:
Segregation accuracies for simulation 3.
Figure:
Example of simulation 3: (a) original /a/ f1(t), (b) mixed signal f(t), (c) fundamental frequency F0(t), (d) segregated signal
.
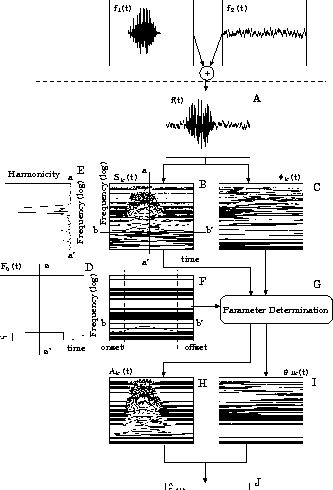 |
To show that the proposed method can segregate the desired vowel from a noisy vowel precisely even in waveforms, we performed three simulations using signals (b)-(d) under the following conditions:
- 1.
- vowel segregation (/a/, /i/, /u/, /e/, /o/) from a noisy vowel: the dataset size was 160 (five vowels, four speakers, four noise signals, and two types of noise);
- 2.
- vowel segregation (/aoi/) from a noisy vowel: the dataset size was 32 (one vowel, four speakers, four noise signals, and two types of noise); and
- 3.
- vowel segregation from another vowel (double vowel condition): one vowel was (/a/, /i/, /u/, /e/, /o/) of the male (mau) or female (fkn) speaker and the other was /aoi/ of the female (fsu) or male (mht) speaker, and the dataset size was 40 (five vowels, two speakers, and four noise signals).
In addition, we compared the performances of the proposed model with those of other typical method (using constraints 1, 8 and, 10) for the above simulations.
The other methods using constraints 1, 8, and 10 correspond to:
- (1)
- extracting the harmonics using the Comb filter and estimating Ak(t) and
 using the Kalman filter,
using the Kalman filter,
- (2)
- extracting the harmonics using the Comb filter, and
- (3)
- doing nothing.
Comparison with condition (1) shows that the proposed method has the advantage of the smoothness of the instantaneous amplitude and phase,
and comparison with condition (2) shows that it has the advantage of the instantaneous phase.
Moreover, comparison with condition (3) shows that the proposed method's segregation accuracy was improved.
The segregation accuracies in the three simulations are shown in Figs. ![[*]](/usr/share/latex2html/icons.gif/cross_ref_motif.gif) , and .
In these figures, the bar height shows the mean of the segregation accuracy and the error bar shows its standard deviation.
The results show that the proposed method obtained better segregation accuracy than the other three methods.
They show that it can segregate the desired vowel from a noisy vowel precisely even in waveforms.
In addition, the comparison between the proposed method and condition (2) shows that the simultaneous signals can be precisely segregated using the instantaneous amplitude and phase.
The comparison with condition (3) shows that the improvements in segregation accuracies at an SNR of 5 dB for simulations 1, 2 (in the case of pink-noise), and 3 were about 9, 7, and 4 dB, respectively.
, and .
In these figures, the bar height shows the mean of the segregation accuracy and the error bar shows its standard deviation.
The results show that the proposed method obtained better segregation accuracy than the other three methods.
They show that it can segregate the desired vowel from a noisy vowel precisely even in waveforms.
In addition, the comparison between the proposed method and condition (2) shows that the simultaneous signals can be precisely segregated using the instantaneous amplitude and phase.
The comparison with condition (3) shows that the improvements in segregation accuracies at an SNR of 5 dB for simulations 1, 2 (in the case of pink-noise), and 3 were about 9, 7, and 4 dB, respectively.
Next: Considerations
Up: Simulations
Previous: Evaluation of the constrains
Masashi Unoki
2000-10-26