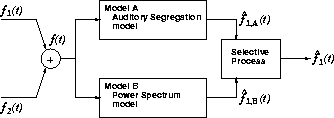
Our computational model of CMR is shown in Fig. ![]() .
This model consists of two models (A and B) and a selection process.
In this model, it is assumed that f1(t) is a sinusoidal signal and f2(t) is two types of noise masker (bandpassed random noise and AM bandpassed random noise) whose center frequency is the same as the signal frequency.
It is also assumed that the localized f1(t) is added to f2(t).
Since the proposed model can observe only mixed signal f(t), it can extract a sinusoidal signal f1(t) using two models (A and B).
Model A is the auditory segregation model we proposed [7].
Model B is the power spectrum model of masking [1].
We consider that in the computational model of CMR these two models work in parallel and extract a sinusoidal signal from the masked signal.
Here, let
.
This model consists of two models (A and B) and a selection process.
In this model, it is assumed that f1(t) is a sinusoidal signal and f2(t) is two types of noise masker (bandpassed random noise and AM bandpassed random noise) whose center frequency is the same as the signal frequency.
It is also assumed that the localized f1(t) is added to f2(t).
Since the proposed model can observe only mixed signal f(t), it can extract a sinusoidal signal f1(t) using two models (A and B).
Model A is the auditory segregation model we proposed [7].
Model B is the power spectrum model of masking [1].
We consider that in the computational model of CMR these two models work in parallel and extract a sinusoidal signal from the masked signal.
Here, let
![]() and
and
![]() be the sinusoidal signals extracted using models A and B, respectively.
The fundamental idea arises from the fact that the masking threshold increases as the masker bandwidth increases up to the bandwidth of the signal auditory filter (1 ERB) and then it either remains constant or decreases depending on the coherency of fluctuations.
In other words, model B can explain part of CMR by using the output of a single auditory filter for the case that the masker bandwidth increases up to 1 ERB, and
Model A can explain part of CMR by using the outputs of multiple auditory filter for the case that the masker bandwidth exceeds over 1 ERB.
be the sinusoidal signals extracted using models A and B, respectively.
The fundamental idea arises from the fact that the masking threshold increases as the masker bandwidth increases up to the bandwidth of the signal auditory filter (1 ERB) and then it either remains constant or decreases depending on the coherency of fluctuations.
In other words, model B can explain part of CMR by using the output of a single auditory filter for the case that the masker bandwidth increases up to 1 ERB, and
Model A can explain part of CMR by using the outputs of multiple auditory filter for the case that the masker bandwidth exceeds over 1 ERB.