目次
音(音声)を聴くとはどういうことであろうか。
我々が生活しているあらゆる環境に音は存在する。何かが動けば音が出る。道具を使えば音が出る。人とのコミュニケーションを行なおうとすれば音(音声)が出る。我々のまわりには音があることはあたりまえになっている。我々がいつも聴いている空気--音は空気の振動であるが--のような存在の音について、この問いに対する答えをどのように見つけ出すかを考えることが、「今後の研究方針」と題した本文の目的である。
動物にとって音を聴くことは、多くは敵から身を守るための危険を察知する、獲物のいる場所を特定し捕獲するための重要な手段である。これらは、音による方向知覚、距離知覚の一例であるが、人間にとっては、音による方向知覚、距離知覚だけではなく、音声の発声・知覚がコミュニケーションの手段としても用いられている。
人間は二足歩行をするようになり、今まで体の前に突き出ていた頭を首の上に据えた。これにより、前の方に出ていた鼻と口が後退して平坦になり、今まではあまり曲がっていなかった声道が大きく折れ曲がった。鼻腔が小さくなって臭いの感度は低下したが、逆に、喉頭が下がり舌骨と喉頭軟骨が分離したことと咽頭の部分が大きくなったことで、舌が大きく自由に動くようになった。これらの結果、人間は、発話器官である舌、アゴ、唇の動きの自由度が増し、様々な音韻を発するための声道の形を作れるようになったのである。
音声生成と知覚は表裏の関係にあり、多様な音韻を生成するためには多様な音韻を聞き分ける能力を持たねばならない。このため、人間においては、音声生成機構の発達と相まって言語音声の知覚機構も発達を遂げたのである。
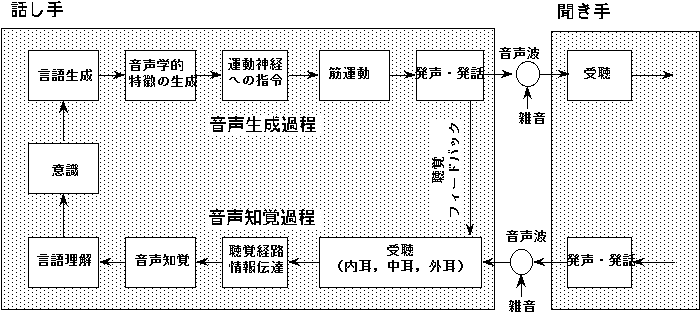
人間が相互にコミュニケーションを行う場合、言葉を発して相手に自分の考え、感情などを伝えようとする一方で、相手が伝えてきた考え、感情などの情報を受け取り、理解して、そして、適切な応答を行う手段が必要である。自分自身の中でこのサイクルが上手くまわることによって、コミュニケーションが保たれる。このサイクルのことを“ことばの鎖”と呼んでいる。
ことばの鎖には、多くの学問分野が関係する。たとえば、
(生成)
意識 → 言語生成 → 音声学的特徴の生成 → 運動司令 → 筋運動 →
心理学、認知科学 生理学、音声学 脳神経学
発声・発話 → 伝播
生理学、物理学(音響学)
(知覚)
伝播 → 受聴 → 聴覚経路 → 音声知覚 → 言語理解 → 意識
物理学 医学・生理学 心理学 認知科学
である。ことばの鎖を研究する上での有用性は、研究分野によって異なるが、共通していることは、音(音声)を生成する・知覚するとはどういうことであろうか、という問いの答えを見つけ出すことに他ならない。生成と知覚は表裏一体であるので、「音を聴く」を解明するためには、ことばの鎖の中での知覚機構を考える必要がある。
工学分野から見れば、ことばの鎖の解明は、「音によるマンマシンインターフェースの実現のための基礎的検討」となる。例として、機械による音声認識は、「ことばの鎖の中の音声知覚過程を工学的に実現する一つの応用問題」、と言うことができる。将来的に“ことばの鎖”がすべて機械の上に実現され、機械と違和感なくコミュニケーションが行われる状況が来るためには、この応用問題を解かなければならない。
ところが、最近の音声認識・合成の研究は、ことばの鎖を巡る音声そのものの特徴を考えるよりも、あらゆる人のあらゆる音声の実例をできるだけたくさん用意しておいて、入力と一番近いものを捜し出し、これによって認識あるいは合成を行なうという、言うなれば大量のパターン処理による特徴抽出の方向に向いている。そして、確かに認識率あるいは音声の明瞭性は向上している。近年の計算機メモリの容量拡大と計算能力の向上の所産であると言うこともできるが、これが、工学的性能の追及以外に、音(音声)を聴くとはどういうことであろうかという問いに有益な何かをもたらすか、は甚だ疑問である。
一方、現在用いられている音声認識方式は、理想的な環境ではほとんど行き着くところまで行き、次のステップとして、どのような環境においても高性能な音声認識を行なう手法の開発が課題となっている。ところが、現在の手法では、あらゆる環境で高性能な音声認識を行なうためには、あらゆる環境を想定しあらゆる実例を用意することが必要である。これはほとんど無理である。
今後より大量のデータを処理することによって少しは認識率を上げることはできるかも知れないが、大量のデータを集めただけの認識率への見返りはあまり期待できない、という声が統計的認識手法(HMMなど)の生まれ故郷であるアメリカからさえ聞こえてくるようになった。
そこで、新しい研究のうねりとして、”音(音声)を聴くことの本質に帰ろう。Fletcherに帰ろう”、あるいは、”聴覚の計算理論を作ろう(人間は聴覚で外界から何を抽出しているのか、それはなぜなのかを探求する)”という研究方向が生まれてきた。すなわち、
“音(音声)を聴くとはどういうことであろうか”という原点にもう一度立ち帰って、音声知覚と音声認識の関係を考え、音声認識・合成のbreakthroughを見つけ出そうとする研究方向である。
”音(音声)を聴くことの本質に帰ろう。Fletcherに帰ろう”の中に出てくるFletcherとは、1910~50年代に米国Bell研究所において、マスキング現象から導かれた聴覚フィルタの概念の提案、音韻明瞭度と単語・文章知覚の関係など音声・音響に関する数々の研究を行なった研究者である。
Fletcherが行なった研究は、今でも、音分析用フィルタバンクの設計、音品質評価の指標などに使われているが、音声知覚に関連する研究についても音声認識・合成の研究の基礎として再度議論し、新たな一歩を踏み出そうという空気が、AT&T Bell研究所を中心にわき上がっている。一方日本では、大量データを用いた統計的認識・合成手法がかなりの成功を納め、日本も主要な役割を演じたせいか、ほとんどの研究者がこの方法の路線上で研究を行なっている。日本でも、音声認識・合成のための新たな研究方向とは何か、そして、その一つの方向が原点(音声知覚)に立ち帰ることかどうか、を議論する場が必要ではないだろうか。
もう一つの研究方向である”聴覚の計算理論を作ろう(人間は聴覚で外界から何を抽出しているのか、それはなぜなのかを探求する)”は、D. Marrが唱えた視覚の計算理論の聴覚版である。
Marrはその著書"Vision"の中で、視知覚の計算モデルを作る場合、どのように計算するか(表現とアルゴリズム)よりも、何を計算するのか(WHAT)そしてそれはなぜなのか(WHY)(計算理論)が重要であることを解いた。現在、音声認識に携わっている工学屋は、どのようにして認識率を上げるか、そしてその表現とアルゴリズムは何か、また物理的に実現するためにはどのようにすれば良いか、という点について研究を進めている。言うなれば、HOWの議論を行っている。一方、心理・生理屋は、筆者が考えるに、人間が実現した機能および特性をあらゆる方法で測定しており、言うなれば、人間におけるHOWの議論を行っている。すなわち、両方ともWHATとWHYの議論がなかなかなされない状況である。しかし、”何を計算するのかそしてそれはなぜなのか”の議論は、異なるカルチャーを持った集団が唯一同じ土俵で語り合える議題であろう。仮に、WHATとWHYのある程度の結論が出るならば、工学屋はそれを実現するためのコンピュータに合ったアルゴリズムを考案すれば良いし、心理・生理屋はWHATとWHYに沿った人間の実現形態の研究ができるのではないだろうか。そして、有益な研究結果はこのような土壌の中から生まれてくるものである、と考えられる。
すなわち、どのような特徴がどのように表現され処理されているのか、それはなぜなのかを、音声知覚、聴覚機構という原点に立ち帰って議論し、音声認識・合成のbreakthroughを見つけ出すことが、これからの研究方向の一つとして存在し、また期待されている。
“音(音声)を聴くとはどういうことであろうか”という問いに答え、また、これを基にして音(音声)に関する新たな研究方向を見つけ出すためには、上に書いた議論を踏まえて、次に示すような目的を持った研究が必要であると考える。
| 音を通して、外界のどのような情報が、聴覚末梢系でどのように処理され、脳内に符号化されるのか、また、なぜこのような方略をとっているのかを、工学、生理学、心理学にまたがった分野での総合的な研究から探求する |
(a) 生理データ、心理データに忠実な聴覚機構のモデル化
生理学的データに忠実なモデルの構築を行なう。たとえば、音分析に関係ある聴覚末梢系、特徴抽出に関係する蝸牛神経核、方向定位に関係する上オリーブ核などの生理データに一致した出力を生む機能モデルを構築する。また、最近の脳機能計測結果も視野に入れたモデル化を試みる。
さらに、心理学的データに対しても忠実なモデルの構築を行なう。心理学的データは、聴覚系および脳全体を一つのブラックボックスと見た場合の入出力関係を示しており、これをモデル化することにより、脳内での特徴抽出、符号化の一端を明らかにする。
モデル化とは、動物の耳、人間の耳の一部と機能的に同じように動くものを作ることであり、知見に忠実なモデル化によって各部位の働きの確認、モデルからの新たな知見の提案が可能となる。さらに、工学的に有用なモデルであれば、音信号処理、音声認識・合成などへの応用も可能となる。
(b) 音による外界の認知(ASA:聴覚情景解析)
音による外界の認知は、動物にとって最も基本的な営みである。この機能の一つであるカクテルパーティ効果についてのモデル化を試みる。
かつて聖徳太子は同時に10人の訴えを聞きそれを処理した、と言われている。我々一般人がこれを真似しようとしてもうまくはいかないだろうが、10人の中の一人の話す内容に注目して聞き取ることは、我々にとってもさして難しいことではない。このように、二つ以上のメッセージが混在していても一方を選択的に聴取可能であるような聴覚上の効果を「カクテルパーティ効果」と呼んでいる。カクテルパーティ効果が生じる原因としては、音の到来方向の違い、音源の特徴の違い、また音声の場合には言語的知識、経験などが関係していると見られている。
そこで、(a)で示した生理データ、心理データに忠実な聴覚機構のモデルの上で、次のような項目についてそれぞれ検討し、カクテルパーティ効果の実現をはかる。
音源方向・距離の推定
音源の分離
聞こえない音の知覚的補間
位相変化、振幅変化に含まれる時間情報の知覚
言語的知識を扱うためのtop-down(AI的手法)とbottom-up(信号処理)の融合
(c) 音声に含まれる情報の解明と制御
音声がどのように脳内で符号化されるのかについて検討を行なう。
音声には、何を話しているかを伝える言語情報と、それ以外に個人性、感情などを伝えるパラ言語情報が含まれている。我々はこれらを音声から巧みに抽出し、人とのコミュニケーションに役立てている。またこれとは別に、視覚から得る情報も用いており、これらが統合されて人とコミュニケーションを行なっている。
そこで、言語情報を得るための音韻/音節/単語/文知覚機構のモデル化、また、パラ言語情報を得るための各種特徴(たとえば基本周波数、発話タイミングなど)の知覚についてのモデル化、さらに、視覚情報と聴覚情報の融合・競合のモデルの構築をテーマとして研究を行なう必要がある。
これらの結果から、音声認識・合成、音声対話に有用な知見が得られるであろう。
このような研究を行うためには、
(1) 心理物理実験による知見の獲得:どのような情報が処理され符号化されているのかを心理物理実験を通して明らかにする。
(2) 計算機による生理学的知見、心理学的知見のモデル化:知見と同じ結果を生み出す知見に忠実な機能モデルを構築し、そのモデルによって各部位の働きの確認、あるいは、モデルからの提案を行なう。また、工学的に有用な場合はこれを応用する。
ことが必要である。すなわち、このような研究を行うためには、工学、心理学、生理学にまたがった分野での総合的な研究が必要なのである。
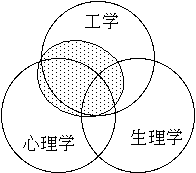
これからは脳の時代と言われており、脳研究に関する通産省、科技庁の大型プロジェクトなども多数発足している。音研究についても、音(音声)を聴くとはどういうことであろうかという問いに答えるためには、脳まで含めた総合的な研究を行なう必要がある。そして、音声認識・合成の工学的な側面だけを見るのではなく、音声知覚・音声生成を含めた“ことばの鎖”の研究、また、“ことばの鎖”に係わる様々な学問分野にまたがった総合的な研究を行なわなければならない。
筆者は、これらの研究の一翼を担えれば、と考えて、本文「今後の研究方針」を執筆した。