ANSPRE: A Method that Boosts the Accuracy Performance of Large Language Models
Researchers develop a new method that enables large language models to answer questions more concisely and accurately
Large language models (LLMs) have demonstrated remarkable potential in open-domain question answering. However, existing models often produce lengthy responses and lack reliable confidence scores. To address these issues, researchers have introduced a new approach called Answer-prefix Generation (ANSPRE). This method generates an 'answer prefix' for LLMs, which guides them to produce high-quality and concise answer phrases as well as reliable confidence scores. This innovative approach can pave the way for widespread applications of LLMs.
Large language models (LLMs) are machine-learning models designed to understand and generate human language. State-of-the-art LLMs have demonstrated outstanding potential in open-domain question answering (ODQA), where the model is tasked with providing answers to factual questions. This is particularly useful in fields such as finance, healthcare, and education. However, LLMs typically rely on their pre-trained knowledge to answer questions, which can become outdated in a constantly changing world.
This limitation can be addressed by using Retrieval-Augmented Generation (RAG) with a pre-trained LLM. In this approach, the question is augmented with documents from a knowledge base. Despite these advancements, LLMs often produce lengthy responses, providing contextual information that can make it difficult and time-consuming to identify the exact answer phrase.
Another important aspect of LLMs is their ability to produce confidence scores, which reflect how certain the model is about the correctness of its answer. These scores are especially crucial in high-risk fields such as finance, law, and healthcare. Although LLMs can generate sequence probabilities for a specific response, this probability is often unreliable in terms of calibration. This means the predicted confidence may not accurately correlate with the probability of correctness and should not be used as a confidence score. The inability to identify the exact answer phrase and produce a reliable confidence score limits the practical application of LLMs.
To address these limitations, a team of researchers from the Japan Advanced Institute of Science and Technology, led by Professor Nguyen Le Minh and including doctoral students Nguyen-Khang Le, Dieu-Hien Nguyen introduced a novel method called Answer-prefix Generation (ANSPRE). "ANSPRE can improve the generation quality of LLMs, allow them to output the exact answer phrase, and produce reliable confidence scores. Additionally, it can be incorporated into any LLM and complex architecture" says Prof. Nguyen. Their study was presented at the European Conference on Artificial Intelligence held on October 19-24.
The main idea of ANSPRE is to add a sequence of text to the LLM prompt that leads to the answer phrase. This sequence of text is called the 'answer prefix'. Prof. Nguyen explains, "Consider the example question, 'What gambling game, requiring two coins to play, was popular in World War I?' An answer prefix for this question could be, 'The gambling game requiring two coins to play that was popular in World War I was ___.' As most LLMs are trained with causal language modeling, using the answer prefix would allow the LLM to generate the exact answer phrase in place of the blank."
Given a question, ANSPRE first generates an answer prefix using selected few-shot examples. The researchers demonstrated that only a few handcrafted examples were sufficient to generate a high-quality answer prefix. ANSPRE then uses an existing retriever to gather relevant documents from the knowledge base, similar to RAG. It combines the document, the question, and the answer prefix, and prompts the LLM to generate the answer phrase. Finally, ANSPRE aggregates the answer phrases and confidence scores across different documents used to answer the question, to produce the final answer.
The researchers demonstrated ANSPRE's versatility by constructing Self-Reflective Answer-Prefix Generation (SELF-ANSPRE), which combines ANSPRE with Self-Reflective RAG (SEFT-RAG). SEFT-RAG improves LLM generation by introducing reflection tokens to decide when and what to retrieve from the knowledge base and rank the responses based on the utility of the documents and the answer. In SELF-ANSPRE the confidence scores from ANSPRE and scores from reflection tokens are combined to generate the final ranking score.
The researchers tested ANSPRE on three ODQA benchmarks and various LLM architectures. The results showed that ANSPRE significantly improves pre-trained and instruction-tuned LLMS, producing high-quality answers and confidence scores that strongly correlate with correctness. Moreover, SELF-ANSPRE significantly enhanced SEFT-RAG. Their analysis also highlighted the importance of each ANSPRE component.
"Our method can lead to more concise and accurate question answering in critical fields like medical diagnosis, legal assistance, and education, and improve customer support. Furthermore, in the long term, our research could foster widespread human-artificial intelligence collaboration by increasing trust in AI systems ," remarks Prof. Nguyen.
Overall, this innovative method marks a significant step forward for LLMs and can lead to their broader application, even in sensitive domains.
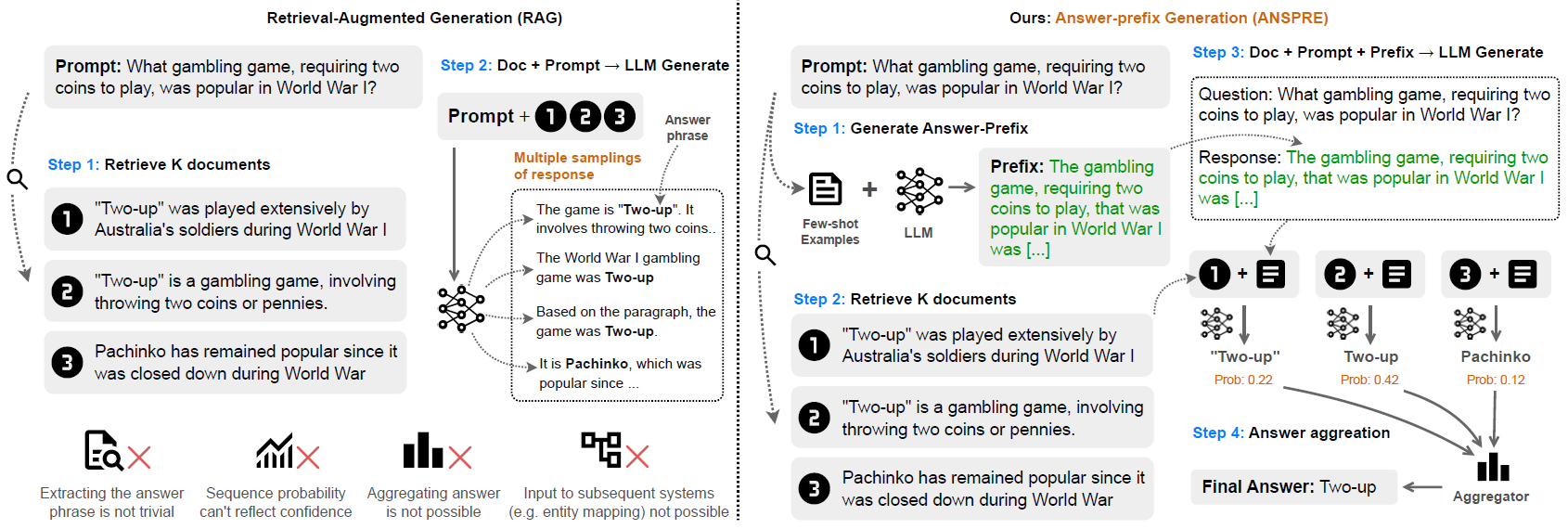
Figure 1. Overview of the proposed method, Answer-prefix Generation compared to ordinary Retrieval-Augmented Generation
Image caption: Answer-prefix Generation (ANSPRE) generates an answer prefix for the prompt question and then retrieves relevant information from the knowledge base like Retrieval-Augmented Generation (RAG) to generate accurate and concise answer phrases.
Image credit: Nguyen Le Minh from JAIST.
License type: Original Content.
Usage restrictions: Cannot be reused without permission.
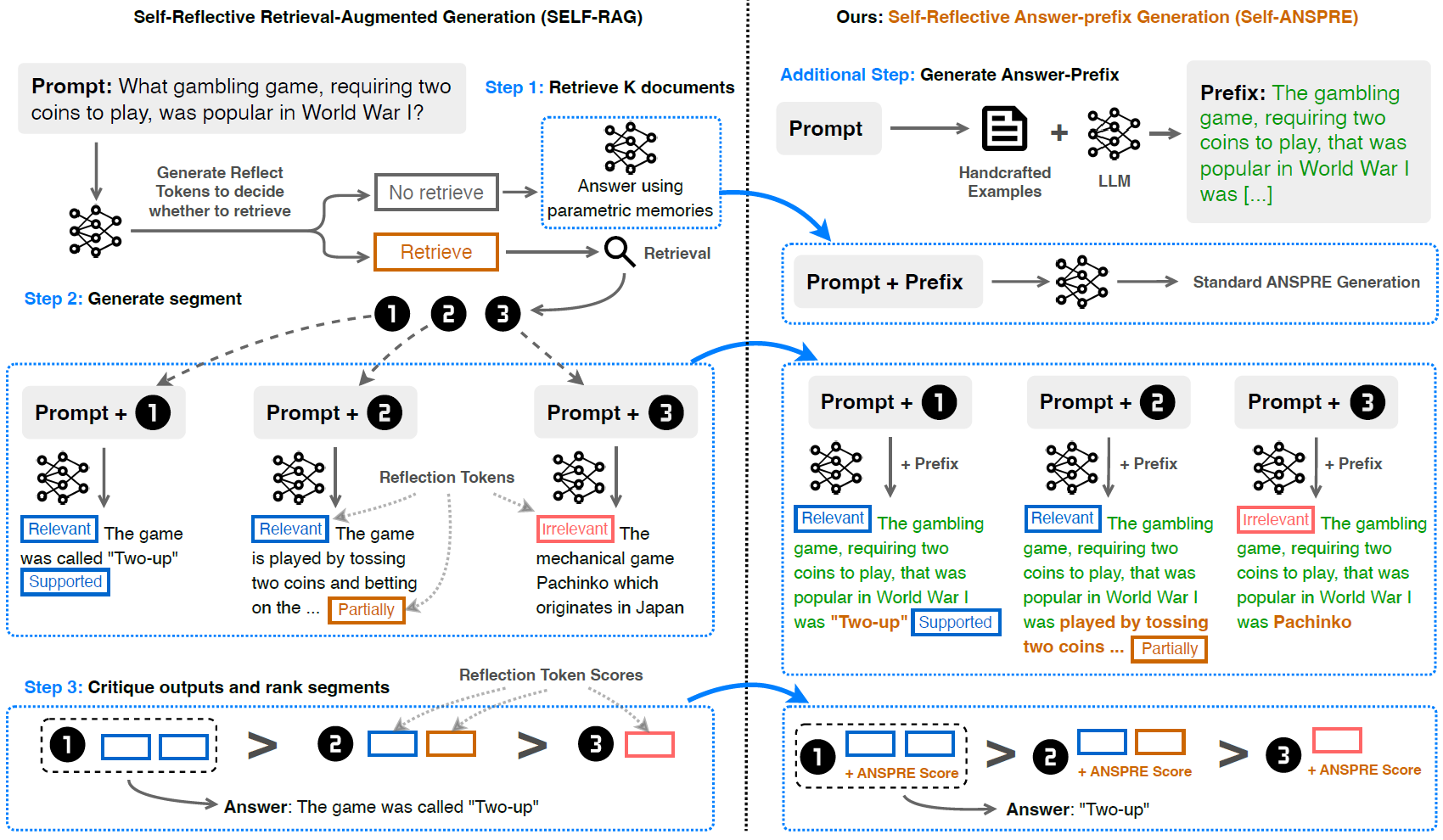
Figure 2. SELF-ANSPRE: Adaptation of the proposed method to Self-Reflective Retrieval-Augmented Generation
Image caption: Self-Reflective Answer-prefix Generation (SELF- ANSPRE) demonstrates that the proposed ANSPRE can be incorporated into any large language model and even into sophisticated systems.
Image credit: Nguyen Le Minh from JAIST.
License type: Original Content.
Usage restrictions: Cannot be reused without permission.
Reference
| Title of original paper: | ANSPRE: Improving Question-Answering in Large Language Models with Answer-Prefix Generation |
| Authors: | Nguyen-Khang Le, Dieu-Hien Nguyen, and Nguyen Le Minh |
| Conference: | European Conference on Artificial Intelligence |
| DOI: | 10.3233/FAIA240778 |
October 18, 2024
