Extraction of the desired signal from noisy signal is a important problem not only in robust speech recognition systems but also in various signal processing systems. The aim of this work is to solve the problem by constructing an auditory segregation model based on auditory scene analysis (ASA).
Bregman[1] reported that the human auditory system uses four psychoacoustically heuristic regularities: (i) common onset and offset; (ii) gradualness of change; (iii) harmonicity; and (iv) changes taken in an acoustic event, related to acoustic events for solving the problem of ASA. Typical models of auditory segregation based on ASA are Brown and Cooke's model[2] and Nakatani et al.'s model[3]. All these models use regularities (i) and (iii), and an amplitude (or power) spectrum as the acoustic feature. Thus they can not extract the desired signal from a noisy signal completely when the signal and noise exist in the same frequency region. And if background noise increases, it seems that these models can not extract the desired signal with high precision.
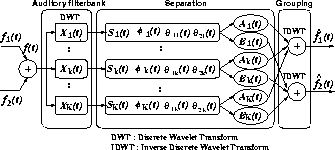
In contrast, we have discussed the need for using not only the amplitude spectrum but also the phase spectrum for completely extracting the desired signal from a noisy signal when both signals exist in the same frequency region[4,5]. In this paper, we present a method for extracting the desired signal from a noisy signal by using physical constraints related to regularities (i) - (iv), as an auditory segregation model. In particular, we consider the problem of extracting the desired signal from the following signals: (a) a noise-added AM complex tone and (b) a noisy synthetic vowel.